Machine learning with the Open Data Cube 
Sign up to the DEA Sandbox to run this notebook interactively from a browser
Compatibility: Notebook currently compatible with both the
NCIandDEA SandboxenvironmentsProducts used: ga_ls8c_nbart_gm_cyear_3
Special requirements: A shapefile of labelled data in shapefile format is required to use this notebook. An example dataset is provided.
Prerequisites: A basic understanding of supervised learning techniques is required. Introduction to statistical learning is a useful resource to begin with - it can be downloaded for free here. The Scikit-learn documentation provides information on the available models and their parameters.
Description
This notebook demonstrates a potential workflow using functions from the dea_tools.classification script to implement a supervised learning landcover classifier within the ODC (Open Data Cube) framework.
For larger model training and prediction implementations this notebook can be adapted into a Python file and run in a distributed fashion.
This example predicts a single class of cultivated / agricultural areas. The notebook demonstrates how to:
Extract the desired ODC data for each labelled area (this becomes our training dataset).
Train a simple decision tree model and adjust parameters.
Predict landcover using trained model on new data.
Evaluate the output of the classification using quantitative metrics and qualitative tools.
This is a quck reference for machine learning on the ODC captured in a single notebook. For a more indepth exploration please use the Scalable Machine Learning series of notebooks. ***
Getting started
To run this analysis, run all the cells in the notebook, starting with the “Load packages” cell.
Load packages
Import Python packages that are used for the analysis.
[1]:
%matplotlib inline
import subprocess as sp
import shapely
import xarray as xr
import rasterio
import datacube
import matplotlib
import pydotplus
import numpy as np
import geopandas as gpd
import matplotlib.pyplot as plt
from io import StringIO
from odc.io.cgroups import get_cpu_quota
from sklearn import tree
from sklearn import model_selection
from sklearn.metrics import accuracy_score
from IPython.display import Image
from datacube.utils import geometry
from datacube.utils.cog import write_cog
import sys
sys.path.insert(1, '../Tools/')
from dea_tools.classification import collect_training_data, predict_xr
import warnings
warnings.filterwarnings("ignore")
Connect to the datacube
Connect to the datacube so we can access DEA data.
[2]:
dc = datacube.Datacube(app='Machine_learning_with_ODC')
Analysis parameters
path: The path to the input shapefile. A default shapefile is provided.field: This is the name of column in your shapefile attribute table that contains the class labelstime: The time range you wish to extract data for, typically the same date the labels were created.zonal_stats: This is an option to calculate the'mean','median', or'std'of the pixel values within each polygon feature, setting it toNonewill result in all pixels being extracted.resolution: The spatial resolution, in metres, to resample the satellite data too e.g. if working with Landsat data, then this should be(-30, 30)output_crs: The coordinate reference system for the data you are querying.ncpus: Set this value to > 1 to parallize the collection of training data. eg.npus=8
If running the notebook for the first time, keep the default settings below. This will demonstrate how the analysis works and provide meaningful results.
[3]:
path = '../Supplementary_data/Machine_learning_with_ODC/example_training_data.shp'
field = 'classnum'
time = ('2015')
zonal_stats = 'median'
resolution = (-30, 30)
output_crs = 'EPSG:3577'
Automatically detect the number of cpus
[4]:
ncpus=round(get_cpu_quota())
print(ncpus)
2
Preview input data and study area
We can load and preview our input data shapefile using geopandas. The shapefile should contain a column with class labels (e.g. classnum below). These labels will be used to train our model.
[5]:
# Load input data shapefile
input_data = gpd.read_file(path)
# Plot first five rows
input_data.head()
[5]:
| classnum | geometry | |
|---|---|---|
| 0 | 112 | POLYGON ((-1521875.000 -3801925.000, -1521900.... |
| 1 | 111 | POLYGON ((-1557925.000 -3801125.000, -1557950.... |
| 2 | 111 | POLYGON ((-1555325.000 -3800000.000, -1555200.... |
| 3 | 111 | POLYGON ((-1552925.000 -3800950.000, -1552925.... |
| 4 | 111 | POLYGON ((-1545475.000 -3800000.000, -1544325.... |
The data can also be explored using the interactive map below. Hover over each individual feature to see a print-out of its unique class label number above the map.
[6]:
# Plot training data in an interactive map
input_data.explore(column=field, legend=False)
[6]:
Extract training data using a shapefile
To train our model, we need to obtain satellite data that corresponds with the labelled input data locations above. The function below takes our shapefile containing class labels and extracts the specified product within these areas into a single array.
[7]:
# Generate a new datacube query object
query = {
'time': time,
'resolution': resolution,
'output_crs': output_crs,
'group_by': 'solar_day',
}
The following function is passed to collect_training_data.
It extracts bands from the ga_ls8c_nbart_gm_cyear_3 product as feature layers along side our labelled data so we can train a supervised model.
The feature function can be modified to extract different combinations of features within the datacube, it is one of the important parts to experiment with when generating your own model.
[8]:
def custom_function(query):
# Initialise datacube
dc = datacube.Datacube(app='custom_feature_layers')
# Load data using query
result = dc.load(product='ga_ls8c_nbart_gm_cyear_3', **query)
return result
Note: The following cell can take several minutes to run. The class labels will be contained in the first column of the output array called model_input, the corresponding variable names captured in the list column_names
[ ]:
column_names, model_input = collect_training_data(gdf=input_data,
dc_query=query,
ncpus=ncpus,
feature_func=custom_function,
field=field,
zonal_stats=zonal_stats)
Preprocessing
Our training data has multiple classes in it. However, we are only trying to predict one class (i.e. class label 111, Cultivated Terrestrial Vegetated) with this model. We therefore remove other classes from our training data by setting the label value for all other classes to 0.
These entries provide counter-examples to help the model distinguish the landcover classes from each other.
[10]:
# Modify the input training data for single class labels
model_input[:, 0] = np.where(model_input[:, 0] == 111, 1, 0)
So that we can access the accuracy of our classification, we split our data into training and testing data. 80% is used for training with 20% held back for testing. When splitting our data, we stratify the training data by the distributions of class membership. This sampling method leads to a similar distribution of class membership in the training data.
[11]:
# Split into training and testing data
model_train, model_test = model_selection.train_test_split(
model_input, stratify=model_input[:, 0], train_size=0.8, random_state=0)
print("Train shape:", model_train.shape)
print("Test shape:", model_test.shape)
Train shape: (173, 11)
Test shape: (44, 11)
Model preparation
This section automatically creates a list of varaible names and their respective indices for each of the training data variables.
Note: To use a custom subset of the satellite bands loaded above to train our data, you can replace
column_names[1:]with a list of selected band names (e.g.['red', 'green', 'blue'])
[12]:
# Select the variables we want to use to train our model
model_variables = column_names[1:]
# Extract relevant indices from the processed shapefile
model_col_indices = [
column_names.index(var_name) for var_name in model_variables
]
A decision tree model is chosen as it is one of the simplest supervised machine learning models we can implement.
Its strengths are its explainability and cheap computational cost.
Parameter tuning can be conducted in the model initialisation below - details on how the different parameters will affect the model are here.
[13]:
# Initialise model
model = tree.DecisionTreeClassifier(max_depth=10)
Train model
The model is fitted / trained using the prepared training data. The fitting process uses the decision tree approach to create a generalised representation of reality based on the training data. This fitted / trained model can then be used to predict which class new data belongs to.
[14]:
# Train model
model.fit(model_train[:, model_col_indices], model_train[:, 0])
[14]:
DecisionTreeClassifier(max_depth=10)
Analyse results
Feature importance
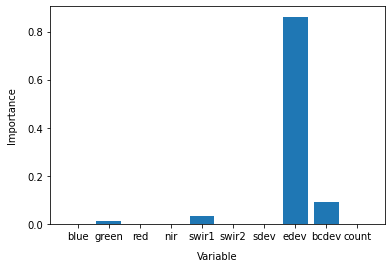
The decision tree classifier allows us to inspect the feature importance of each input variable. Feature importance represents the relative contribution of each variable in predicting the desired landcover class. When summed, the importance of all variables should add up to 1.0.
[15]:
# This shows the feature importance of the input features for predicting the class labels provided
plt.bar(x=model_variables, height=model.feature_importances_)
plt.gca().set_ylabel('Importance', labelpad=10)
plt.gca().set_xlabel('Variable', labelpad=10);
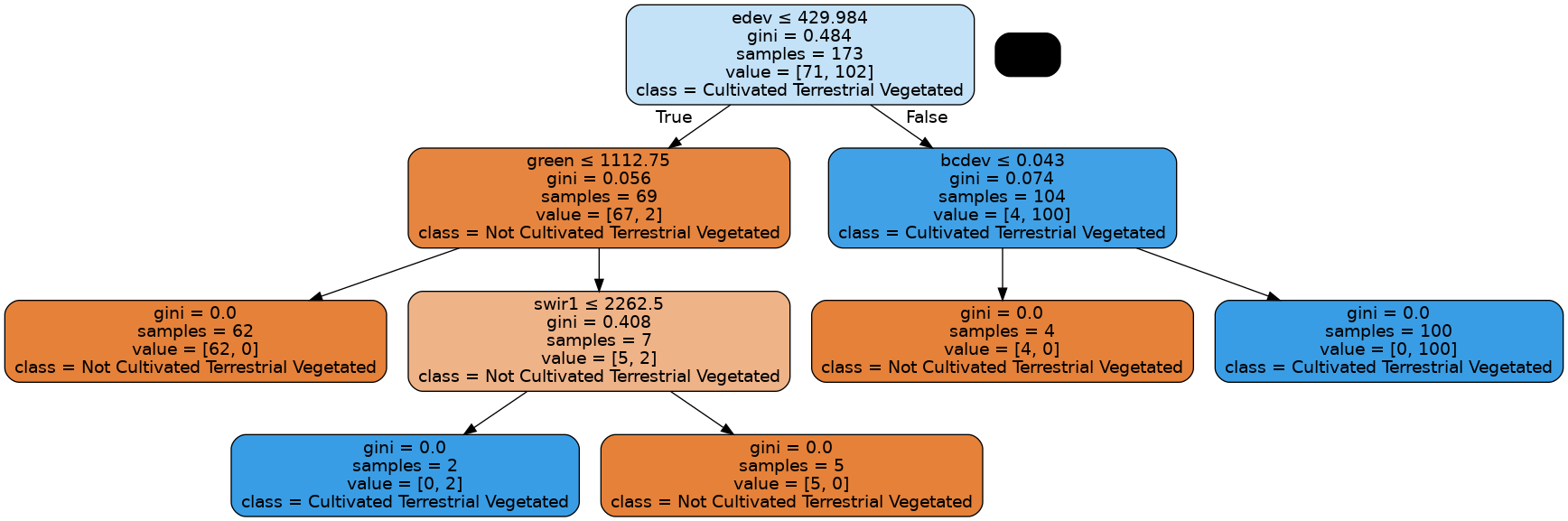
This decision tree representation visualises the trained model. Here we can see that the model decides which landcover class to assign based on the value of the important variables in the plot above.
The gini value shown in the tree represents the decrease in node impurity. This can also be understood as how heterogeneous the labels are (small values indicating better results). This metric is used by the decision tree to determine how to split the data into smaller groups.
[16]:
# Prepare a dictionary of class names
class_names = {
1: 'Cultivated Terrestrial Vegetated',
0: 'Not Cultivated Terrestrial Vegetated'
}
# Get list of unique classes in model
class_codes = np.unique(model_train[:, 0])
class_names_in_model = [class_names[k] for k in class_codes]
# Plot decision tree
dot_data = StringIO()
tree.export_graphviz(model,
out_file=dot_data,
feature_names=model_variables,
class_names=class_names_in_model,
filled=True,
rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
[16]:
Accuracy
We can use the 20% sample of test data we partitioned earlier to test the accuracy of the trained model on this new, “unseen” data.
An accuracy value of 1.0 indicates that the model was able to correctly predict 100% of the classes in the test data.
[17]:
predictions = model.predict(model_test[:, model_col_indices])
accuracy_score(predictions, model_test[:, 0])
[17]:
1.0
Prediction
Now that we have a trained model, we can load new data and use the predict_xr function to predict landcover classes.
The trained model can technically be used to classify any dataset or product with the same bands as the data originally used to train the data. However, it is typically highly advisable to classify data from the same product that the data was originally trained on.
[18]:
# Get extent from input shapefile
xmin, ymin, xmax, ymax = input_data.unary_union.bounds
# Set up the query parameters
query = {
'time': time,
'x': (xmin, xmax),
'y': (ymin, ymax),
'crs': 'EPSG:3577',
'resolution': resolution
}
# Use custom function to generate input data
input_data = custom_function(query)
Once the data has been loaded, we can classify it using DEA predict_xr function:
[19]:
# Predict landcover using the trained model
predicted = predict_xr(model, input_data, clean=True)
predicting...
Plotting
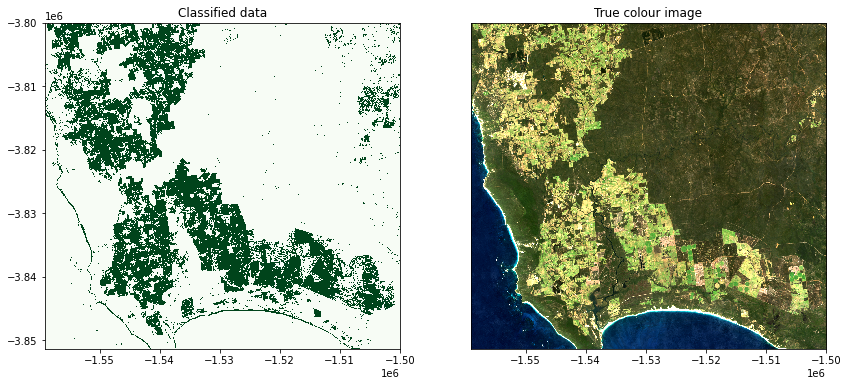
To qualitatively evaluate how well the classification performed, we can plot the classifed/predicted data next to our input satellite imagery.
Note: The output below is unlikely to be optimal the first time the classification is run. The model training process is one of experimentation and assumption checking that occurs in an iterative cycle - you may need to revisit the steps above and make changes to model parameters or input training data until you achieve a satisfactory result.
[20]:
# Set up plot
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Plot classified image
predicted.Predictions.plot(ax=axes[0],
cmap='Greens',
add_labels=False,
add_colorbar=False)
# Plot true colour image
(input_data[['red', 'green', 'blue']]
.squeeze('time')
.to_array()
.plot.imshow(ax=axes[1], robust=True, add_labels=False))
# Remove axis on right plot
axes[1].get_yaxis().set_visible(False)
# Add plot titles
axes[0].set_title('Classified data')
axes[1].set_title('True colour image');
Exporting classification
We can now export the predicted landcover out to a GeoTIFF .tif file. This file can be loaded into GIS software (e.g. QGIS, ArcMap) to be inspected more closely.
[21]:
# Write the predicted data out to a GeoTIFF
write_cog(predicted.Predictions,
'predicted.tif',
overwrite=True)
[21]:
PosixPath('predicted.tif')
Additional information
License: The code in this notebook is licensed under the Apache License, Version 2.0. Digital Earth Australia data is licensed under the Creative Commons by Attribution 4.0 license.
Contact: If you need assistance, please post a question on the Open Data Cube Slack channel or on the GIS Stack Exchange using the open-data-cube tag (you can view previously asked questions here). If you would like to report an issue with this notebook, you can file one on
GitHub.
Last modified: December 2023
Compatible datacube version:
[22]:
print(datacube.__version__)
1.8.6
Tags
Tags: NCI compatible, sandbox compatible, landsat 8, annual geomedian, predict_xr, get_training_data_for_shp, machine learning, decision tree